
운영체제에서 CPU 사용률(CPU Utilization)을 극대화하려면 멀티프로그래밍이 필수다.
그러나, 하나의 CPU 코어는 동시에 하나의 프로세스만 실행할 수 있다.
이 때문에 CPU 스케줄링이 필요하다.
스케줄링 알고리즘은 프로세스의 실행을 효율적으로 관리해 시스템 성능을 최적화하고,
각종 성능 지표(CPU Utilization, Response Time 등)를 개선하는 데 초점이 맞춰져 있다.
CPU 스케줄링과 프로세스 실행 과정
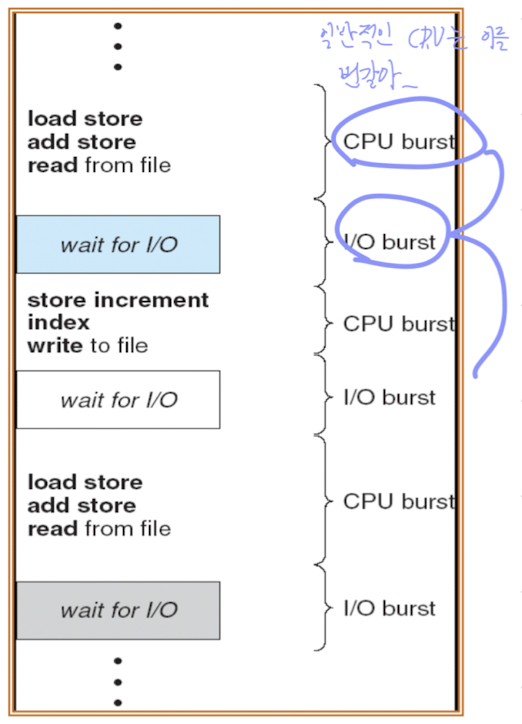
CPU-I/O Burst Cycle
프로세스 실행은 CPU 실행(CPU Execution)과 I/O 대기(I/O Wait)가 반복되는 사이클로 이루어진다.
CPU burst는 일반적으로 짧은 CPU burst가 많은 I/O bound 작업과 긴 CPU burst가 적은 작업으로 구성된다.
CPU 스케줄러: 역할과 동작 💻
CPU 스케줄러는 다음 두 가지를 수행한다.
- Ready 상태의 프로세스 중 하나를 골라 CPU에 할당.
- Context Switching을 통해 CPU를 작업에 넘긴다.
스케줄링은 다음 상황에서 동작한다:
- Running → Blocking (ex. I/O 요청 발생)
- Running → Ready (ex. time quantum 만료)
- Blocking → Ready (ex. I/O 완료)
- Running → Terminated (작업 완료)
주요 스케줄링 알고리즘 비교 👀
1. First In, First Out (FIFO) ; First Come, First Served(FCFS)
FIFO는 간단하고 비선점형(non-preemptive)으로 동작한다.
- 장점: 간단하여 쉽게 구현 가능.
- 단점: Convoy Effect 발생.
Convoy Effect란?
긴 작업이 짧은 작업들 앞에 있을 때 발생하는 문제.
긴 작업이 CPU를 독점하는 동안, 짧은 작업들이 대기 상태로 전환되고,
결과적으로 CPU와 I/O 장치 사용률이 저하된다.
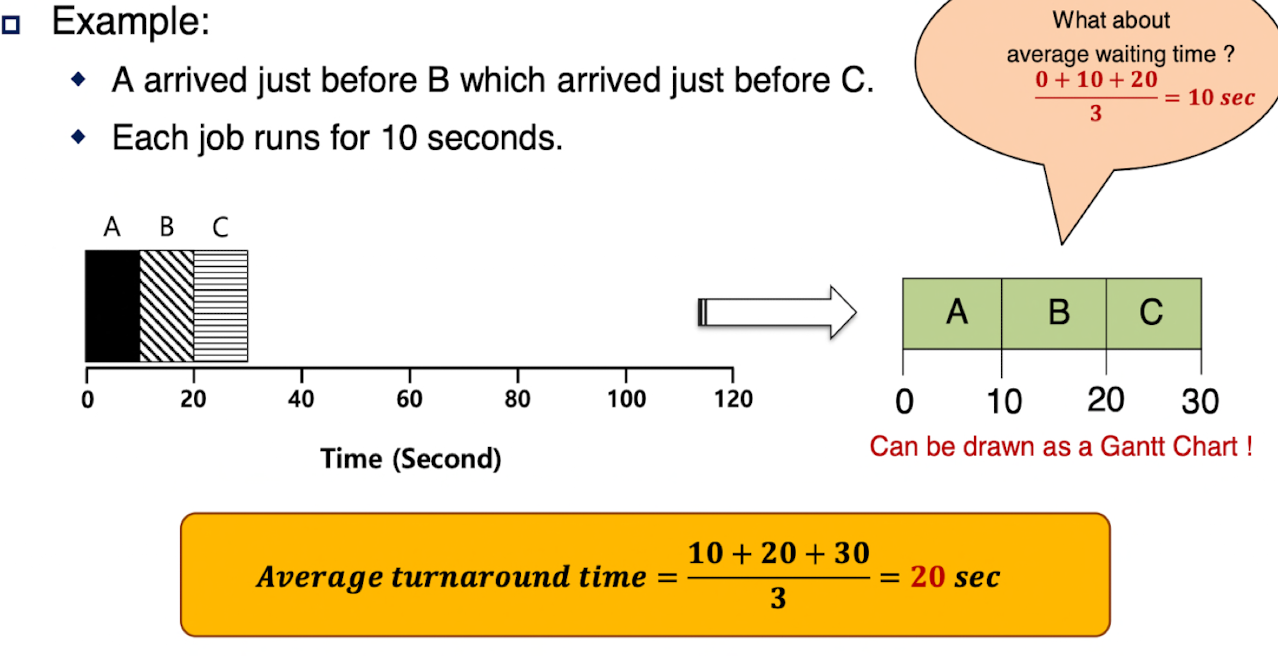
2. Shortest Job First (SJF)
소량 구매 계산대처럼, 가장 짧은 작업을 먼저 실행하는 방식이다.
- 장점: 평균 대기 시간과 처리 완료 시간(turnaround time)을 최소화.
- 단점: 다음 작업의 길이를 예측해야 한다는 점에서 실효성이 떨어짐.
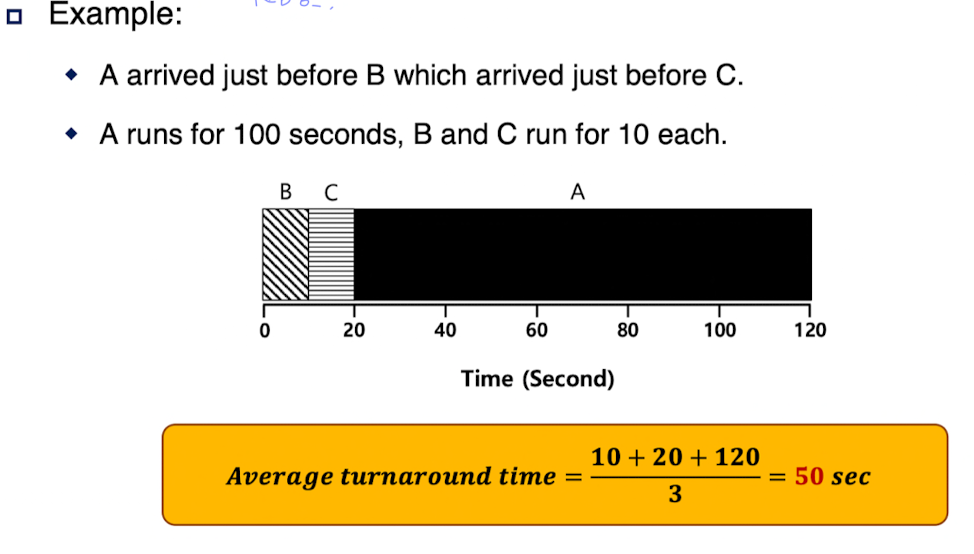
Job들이 아무 때나 들어올 수 있다면: B, C가 A보다 조금 늦게 도착해 convoy effect가 다시 발생한다.
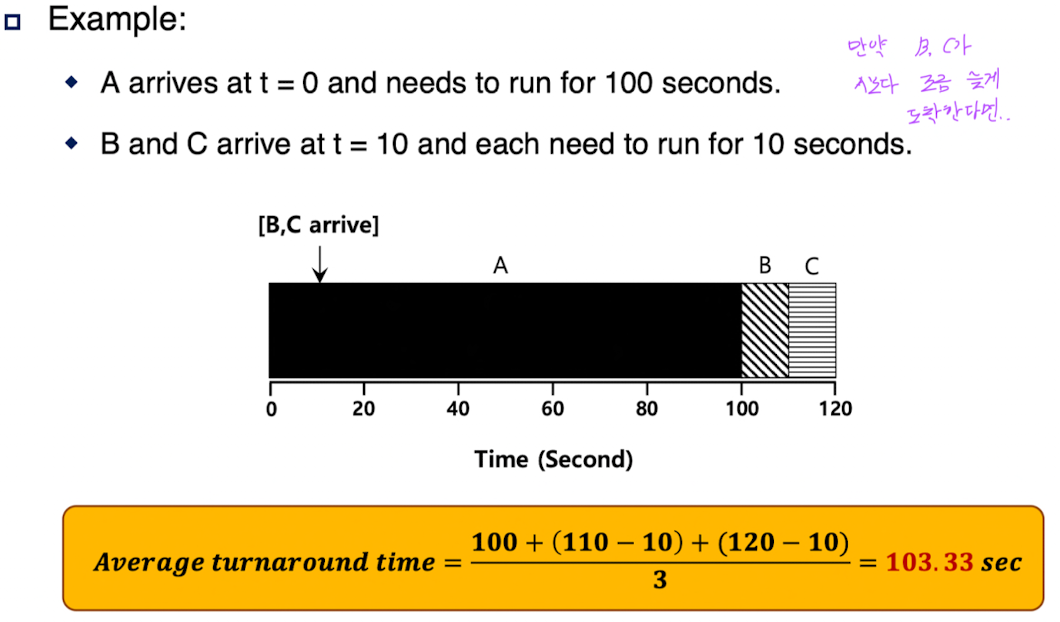
3. Shortest Time to Completion First (STCF)
SJF의 선점형(preemptive) 버전.
현재 실행 중인 작업보다 남은 실행 시간이 더 짧은 작업이 들어오면 선점한다.
CPU Burst 예측
SJF와 STCF는 다음 CPU burst를 예측해야 효과적이다.
이를 위해 Exponential Averaging을 사용해 과거 데이터를 기반으로 CPU burst를 예측한다.
- $\alpha = 0$: 이전 예측을 그대로 사용. ($τ_{n+1}=τ_n$ )
- $\alpha = 1$: 직전 CPU burst 값을 그대로 반영. ($τ_{n+1}=t_n$ )
$$
\tau_{n+1} = \alpha t_n + (1-\alpha)\tau_n
$$
이 식은 다음과 같이 과거 CPU burst를 가중 평균으로 반영한다.
$$
τ_{n+1}=\alpha t_n + (1-\alpha)τ_n \\
= \alpha t_n + (1-\alpha){\alpha t_{n-1} + (1-\alpha)τ_{n-1}} \\
= \alpha t_n + \alpha(1-\alpha)t_{n-1}+ (1-\alpha)^2 τ_{n-1} \\
... \\
= \alpha t_n + (1-\alpha) \alpha t_{n-1}\ ... +\ ... \ + (1-\alpha)^{n+1}τ_0
$$
$0 \leq \alpha \leq 1$이므로, 직전 값이 weight가 제일 크고, 예전으로 갈수록 weight가 작아진다.
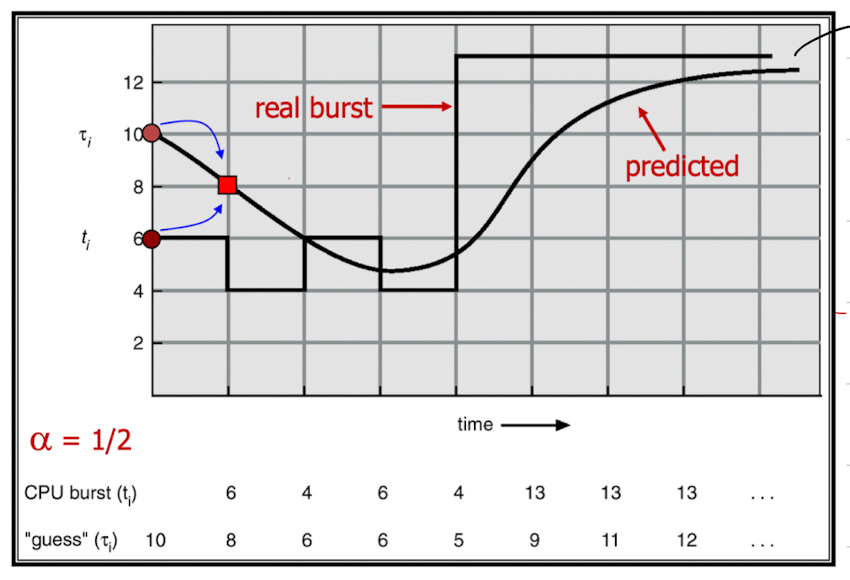
그래프에서: 예측값이 실제를 쫓아가는 것을 더 잘 반영하려면 ⍺
값을 더 크게 (갑자기 튀는 것은 잘 따라갈 것)
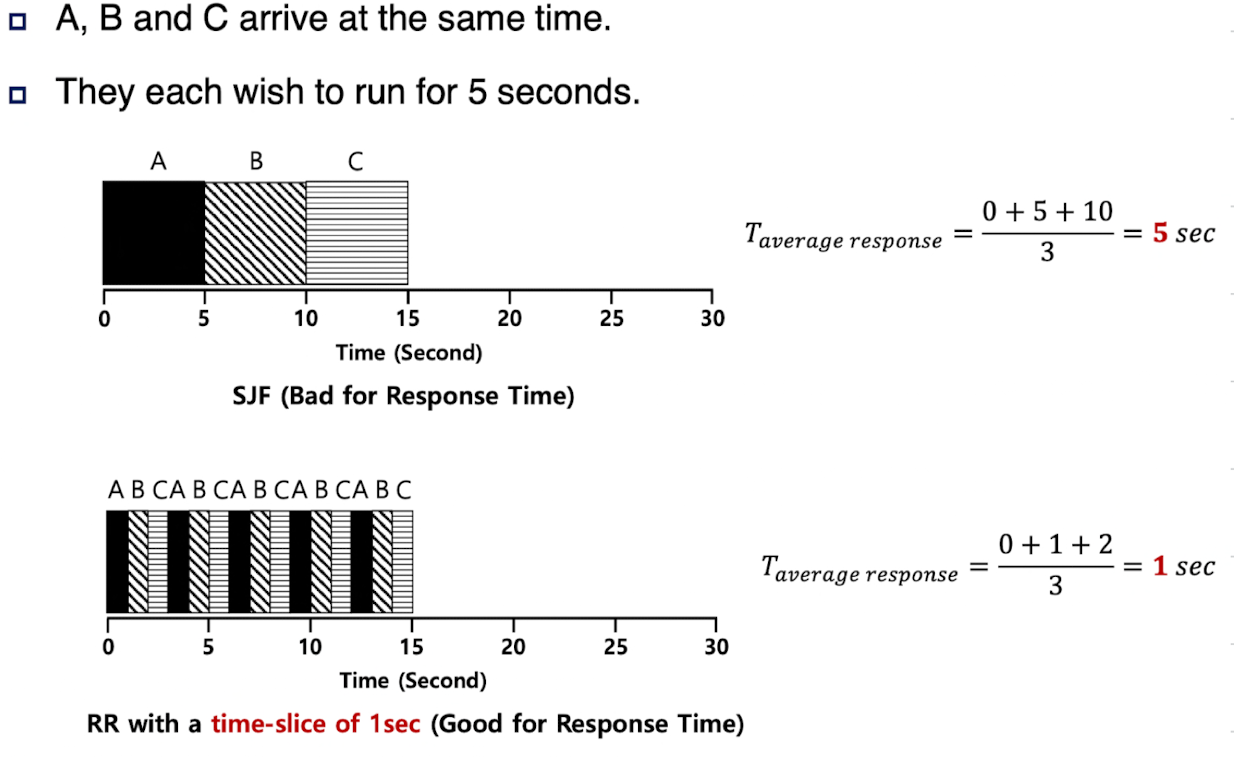
Response Time (Scheduling metric)
Job arrives ~ first time scheduled
$$
T_{response}=T_{firstrun} - T_{arrival}
$$
STCF 류의 정책들은 response time이 좋지 않다. (Turnaround time 측면에선 좋다)
→ Response time이 좋은 Scheduler를 고안하게 되었다.
4. Round Robin (RR)
시간 할당량(time quantum)을 설정해, 각 프로세스가 할당된 시간만큼 CPU를 사용하도록 한다.
각 process는 time quantum만큼의 작은 CPU time을 할당받는다. (10~100msec)
이 시간이 지나면, ready queue의 맨 끝으로 강제 이동.
time slice의 길이는 timer-interrupt 주기의 배수여야 한다.
Ready queue에 n개의 process가 있고, time quantum이 q라면, 각 process는 최대 $(n-1) \times q$까지만 기다린다.
- 장점: 각 프로세스가 공정하게 CPU를 사용할 수 있음.
- 단점: time quantum 설정에 따라 성능이 크게 좌우됨.

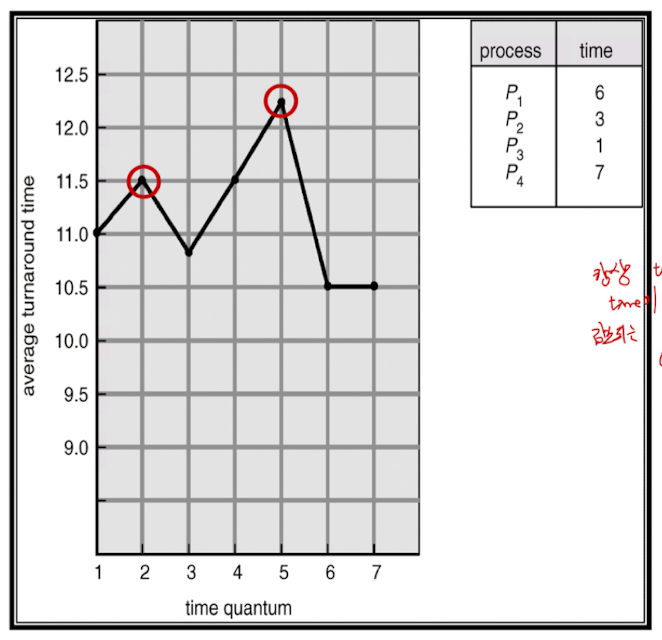
Time Quantum 설정의 영향
q가 커질수록 → FCFS에 가까워진다. (Response time ↑, Turnaround ↓)q가 작으면 → Context Switch 비용 증가 (Response time ↓, Turnaround ↑)
(context switching 하는 시간보다 q가 짧을 수는 없다)
- Time slice가 짧을수록, response time은 줄어들고, context switching 비용이 전체 performance를 잠식해 나간다.
- Time slice가 길수록 switching 비용이 중화(amortize)되고, response time이 증가한다.
(FIFO에 가까워진다. Turnaround time ↓, Response time ↑ : Tradeoff)
만약 Time Quantum이 너무 크면, FCFS policy가 되는데, 항상 turnaround time이 감소되는 것은 아니다.
[!NOTE]
80%의 CPU burst가 time quantum보다 짧을 때 성능이 제일 좋다.
성능 지표: Scheduling의 기준 🎯
스케줄링 알고리즘의 성능은 다양한 지표로 평가된다.
- CPU Utilization: CPU를 최대한 바쁘게 사용.
- Throughput: 단위 시간 동안 완료된 작업 수.
- Turnaround Time: 작업 제출 → 완료까지 걸린 시간.
- Waiting Time: Ready Queue에서 대기한 시간.
- Response Time: 작업 제출 → 처음 실행되기까지 걸린 시간.
스케줄링 알고리즘은 CPU Utilization과 Throughput을 최대화하고,
Turnaround Time, Waiting Time, Response Time을 최소화하는 데 초점을 둔다.
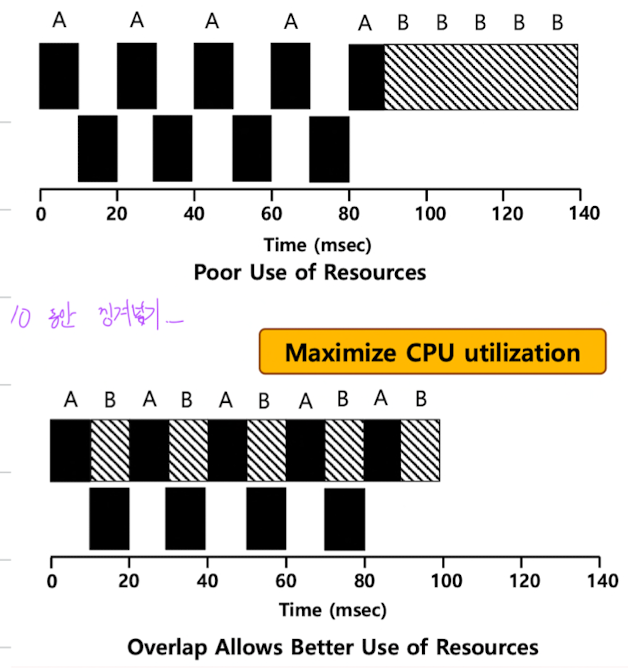
I/O와 Scheduling의 관계
현실적인 작업은 I/O 연산을 포함한다.
I/O 요청이 발생하면 프로세스는 Blocked 상태로 전환되고, 다른 작업이 실행된다.
이로 인해 CPU와 I/O 장치가 서로 교대로 사용되며 자원의 활용도를 높인다.
마무리하며 🎉
스케줄링은 운영체제 성능을 좌우하는 핵심 기술이다.
FIFO, SJF, STCF, RR은 각각의 장단점이 있으며, 사용 환경에 따라 최적의 알고리즘을 선택해야 한다.
다음 글에서는 MLFQ(Multi-Level Feedback Queue)를 살펴볼 예정이다!
'Computer Science > OS' 카테고리의 다른 글
| 2-5. Virtualization: Multiprocessor Scheduling (0) | 2024.12.21 |
|---|---|
| 2-5. Virtualization: Multi-Level Feedback Queue (0) | 2024.11.05 |
| 2-3. Virtualization: Limited Direct Execution (1) | 2024.11.04 |
| 2-2. Virtualization: 파일 디스크립터와 입출력 관리 (0) | 2024.11.03 |
| 2-1. Virtualization: 프로세스 관리와 자료구조, Process API (0) | 2024.11.03 |



